Sato Lab./Sugano Lab.
Sato Lab./Sugano Lab.
Y. Sato Lab.
Sugano Lab.
News
Publications
Contact
Resources
Internal Wiki
English
日本語
Recent Publications
» List of All Publications
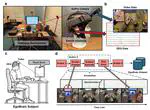
EgoBrain: Synergizing Minds and Eyes For Human Action Understanding
The integration of brain-computer interfaces (BCIs), in particular electroencephalography (EEG), with artificial intelligence (AI) has …
Nie Lin
,
Yansen Wang
,
Dongqi Han
,
Weibang Jiang
,
Jingyuan Li
,
Ryosuke Furuta
,
Yoichi Sato
,
Dongsheng Li
Cite
Bridging Perspectives: A Survey on Cross-view Collaborative Intelligence with Egocentric-Exocentric Vision
Perceiving the world from both egocentric (first-person) and exocentric (third-person) perspectives is fundamental to human cognition, …
Yuping He
,
Yifei Huang
,
Guo Chen
,
Lidong Lu
,
Baoqi Pei
,
Jilan Xu
,
Tong Lu
,
Yoichi Sato
PDF
Cite
UniGaze: Towards Universal Gaze Estimation via Large-scale Pre-Training
Despite decades of research on data collection and model architectures, current gaze estimation models encounter significant challenges …
Jiawei Qin
,
Xucong Zhang
,
Yusuke Sugano
PDF
Cite
Code
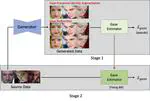
Learning-by-Generation: Enhancing Gaze Estimation via Controllable Generative Data and Two-Stage Training
Generalization to unseen environments is crucial in appearance-based gaze estimation but is primarily hindered by limitations in …
Jiawei Qin
,
Xueting Wang
,
Yusuke Sugano
PDF
Cite
DOI
Robust Long-term Test-Time Adaptation for 3D Human Pose Estimation through Motion Discretization
Online test-time adaptation addresses the train-test domain gap by adapting the model on unlabeled streaming test inputs before making …
Yilin Wen
,
Kechuan Dong
,
Yusuke Sugano
PDF
Cite
DOI
Generative Modeling of Shape-Dependent Self-Contact Human Poses
One can hardly model self-contact of human poses without considering underlying body shapes. For example, the pose of rubbing a belly …
Takehiko Ohkawa
,
Jihyun Lee
,
Shunsuke Saito
,
Jason Saragih
,
Fabian Prada
,
Yichen Xu
,
Shoou-I Yu
,
Ryosuke Furuta
,
Yoichi Sato
,
Takaaki Shiratori
PDF
Cite
Code
AssemblyHands-X: Modeling 3D Hand-Body Coordination for Understanding Bimanual Human Activities
Bimanual human activities inherently involve coordinated movements of both hands and body. However, the impact of this coordination in …
Tatsuro Banno
,
Takehiko Ohkawa
,
Ruicong Liu
,
Ryosuke Furuta
,
Yoichi Sato
PDF
Cite
DOI
Leveraging RGB Images for Pre-Training of Event-Based Hand Pose Estimation
This paper presents RPEP, the first pre-training method for event-based 3D hand pose estimation using labeled RGB images and unpaired, …
Ruicong Liu
,
Takehiko Ohkawa
,
Tze Ho Elden Tse
,
Mingfang Zhang
,
Angela Yao
,
Yoichi Sato
PDF
Cite
EgoInstruct: An Egocentric Video Dataset of Face-to-face Instructional Interactions with Multi-modal LLM Benchmarking
Analyzing instructional interactions between an instructor and a learner who are co-present in the same physical space is a critical …
Yuki Sakai
,
Ryosuke Furuta
,
Juichun Yen
,
Yoichi Sato
PDF
Cite
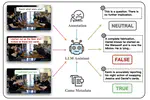
Can MLLMs Read the Room? A Multimodal Benchmark for Verifying Truthfulness in Multi-Party Social Interactions
As AI systems become increasingly integrated into human lives, endowing them with robust social intelligence has emerged as a critical …
Caixin Kang
,
Yifei Huang
,
Liangyang Ouyang
,
Mingfang Zhang
,
Yoichi Sato
PDF
Cite
DOI
See all publications
Cite
×