Abstract
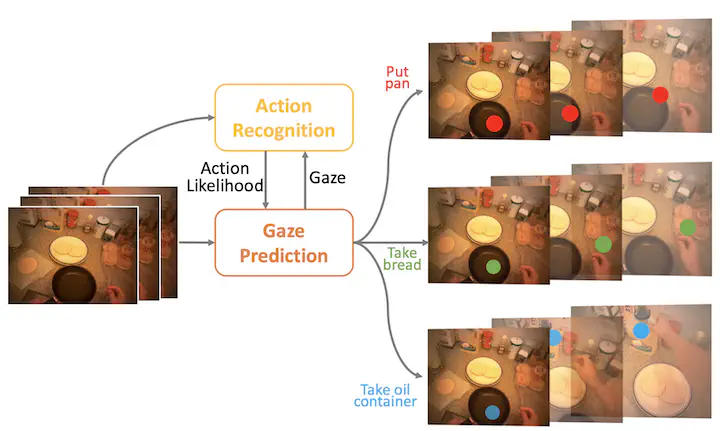
In this work, we address two coupled tasks of gaze prediction and action recognition in egocentric videos by exploring their mutual context: the information from gaze prediction facilitates action recognition and vice versa. Our assumption is that during the procedure of performing a manipulation task, on the one hand, what a person is doing determines where the person is looking at. On the other hand, the gaze location reveals gaze regions which contain important and information about the undergoing action and also the non-gaze regions that include complimentary clues for differentiating some fine-grained actions. We propose a novel mutual context network (MCN) that jointly learns action-dependent gaze prediction and gaze-guided action recognition in an end-to-end manner. Experiments on multiple egocentric video datasets demonstrate that our MCN achieves state-of-the-art performance of both gaze prediction and action recognition. The experiments also show that action-dependent gaze patterns could be learned with our method.