Abstract
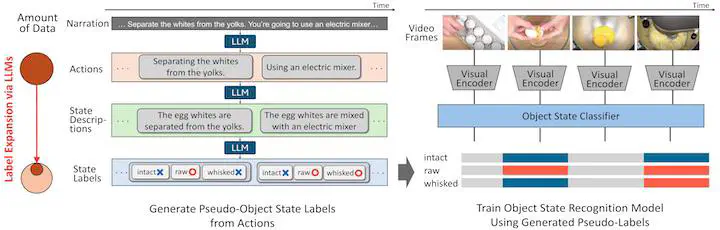
Recognizing the states of objects in a video is crucial in understanding the scene beyond actions and objects. For instance, an egg can be raw, cracked, and whisked while cooking an omelet, and these states can coexist simultaneously (an egg can be both raw and whisked). However, most existing research assumes a single object state change (e.g., uncracked -> cracked), overlooking the coexisting nature of multiple object states and the influence of past states on the current state. We formulate object state recognition as a multi-label classification task that explicitly handles multiple states. We then propose to learn multiple object states from narrated videos by leveraging large language models (LLMs) to generate pseudo-labels from the transcribed narrations, capturing the influence of past states. The challenge is that narrations mostly describe human actions in the video but rarely explain object states. Therefore, we use the LLMs knowledge of the relationship between actions and states to derive the missing object states. We further accumulate the derived object states to consider past state contexts to infer current object state pseudo-labels. We newly collect a dataset called the Multiple Object States Transition (MOST) dataset, which includes manual multi-label annotation for evaluation purposes, covering 60 object states across six object categories. Experimental results show that our model trained on LLM-generated pseudo-labels significantly outperforms strong vision-language models, demonstrating the effectiveness of our pseudo-labeling framework that considers past context via LLMs.