佐藤研究室/菅野研究室
佐藤研究室/菅野研究室
佐藤 (洋) 研究室
菅野研究室
ニュース
発表文献
連絡先
リソース
内部ページ
日本語
English
最近の発表文献
» 全発表文献リスト
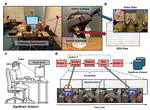
EgoBrain: Synergizing Minds and Eyes For Human Action Understanding
The integration of brain-computer interfaces (BCIs), in particular electroencephalography (EEG), with artificial intelligence (AI) has …
Nie Lin
,
Yansen Wang
,
Dongqi Han
,
Weibang Jiang
,
Jingyuan Li
,
Ryosuke Furuta
,
Yoichi Sato
,
Dongsheng Li
引用
Bridging Perspectives: A Survey on Cross-view Collaborative Intelligence with Egocentric-Exocentric Vision
Perceiving the world from both egocentric (first-person) and exocentric (third-person) perspectives is fundamental to human cognition, …
Yuping He
,
Yifei Huang
,
Guo Chen
,
Lidong Lu
,
Baoqi Pei
,
Jilan Xu
,
Tong Lu
,
Yoichi Sato
引用
UniGaze: Towards Universal Gaze Estimation via Large-scale Pre-Training
Despite decades of research on data collection and model architectures, current gaze estimation models encounter significant challenges …
Jiawei Qin
,
Xucong Zhang
,
Yusuke Sugano
PDF
引用
ソースコード
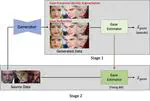
Learning-by-Generation: Enhancing Gaze Estimation via Controllable Generative Data and Two-Stage Training
Generalization to unseen environments is crucial in appearance-based gaze estimation but is primarily hindered by limitations in …
Jiawei Qin
,
Xueting Wang
,
Yusuke Sugano
PDF
引用
DOI
Robust Long-term Test-Time Adaptation for 3D Human Pose Estimation through Motion Discretization
Online test-time adaptation addresses the train-test domain gap by adapting the model on unlabeled streaming test inputs before making …
Yilin Wen
,
Kechuan Dong
,
Yusuke Sugano
引用
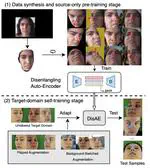
Domain-Adaptive Full-Face Gaze Estimation via Novel-View-Synthesis and Feature Disentanglement
Along with the recent development of deep neural networks, appearance-based gaze estimation has succeeded considerably when training …
Jiawei Qin
,
Takuru Shimoyama
,
Xucong Zhang
,
Yusuke Sugano
PDF
引用
ソースコード
DOI
Data-driven Head Motion Generation through Natural Gaze-Head Coordination
We present the first data-driven approach to model temporal gaze-head coordination from large-scale in-the-wild facial videos. To …
Xiaohan Liu
,
Yilin Wen
,
Yusuke Sugano
PDF
引用
プロジェクト
DOI
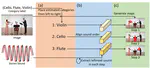
Audio-visual localization based on spatial relative sound order
Sound localization is one of the essential tasks in audio-visual learning. Especially, stereo sound localization methods have been …
Tomoya Sato
,
Yusuke Sugano
,
Yoichi Sato
PDF
引用
DOI
Gazing Into Missteps: Leveraging Eye-Gaze for Unsupervised Mistake Detection in Egocentric Videos of Skilled Human Activities
We address the challenge of unsupervised mistake detection in egocentric video of skilled human activities through the analysis of gaze …
Michele Mazzamuto
,
Antonino Furnari
,
Yoichi Sato
,
Giovanni Maria Farinella
PDF
引用
SiMHand: Mining Similar Hands for Large-Scale 3D Hand Pose Pre-training
We present a framework for pre-training of 3D hand pose estimation from in-the-wild hand images sharing with similar hand …
Nie Lin
,
Takehiko Ohkawa
,
Yifei Huang
,
Mingfang Zhang
,
Minjie Cai
,
Ming Li
,
Ryosuke Furuta
,
Yoichi Sato
PDF
引用
ソースコード
発表文献一覧
引用
×