Gaze Scanpath Transformer: Predicting Visual Search Target by Spatiotemporal Semantic Modeling of Gaze Scanpath
概要
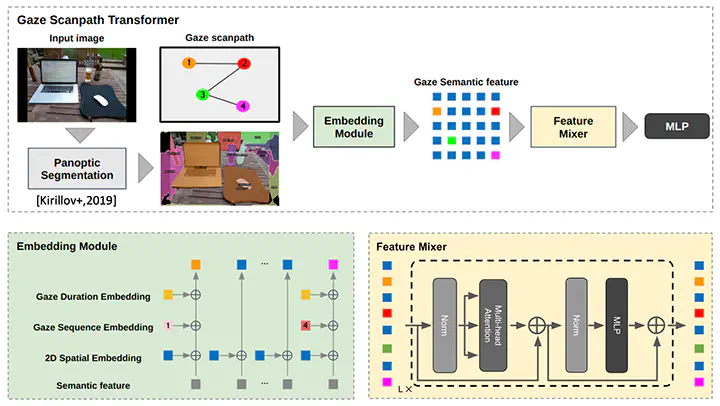
We introduce a new method called the Gaze Scanpath Transformer for predicting a search target category during a visual search task. Previous methods for estimating visual search targets focus solely on the image features at gaze fixation positions. As a result the previous methods are unable to take into account the spatiotemporal information of gaze scanpaths and lack consideration of the semantic interrelationships between objects on gaze fixations. In contrast our method can estimate a visual search target based on the spatiotemporal information of a gaze scanpath and interrelationships among image semantic features at gaze fixation positions. This is achieved by embedding the position and the duration of each fixation and the order of fixations into the image semantic features and by using the model’s attention mechanism to facilitate information exchange and emphasis on image semantic features at gaze fixation positions. Evaluation using the COCO-Search18 dataset demonstrates that our proposed method achieves significant performance improvements over other state-of-the-art baseline models for search target prediction.