概要
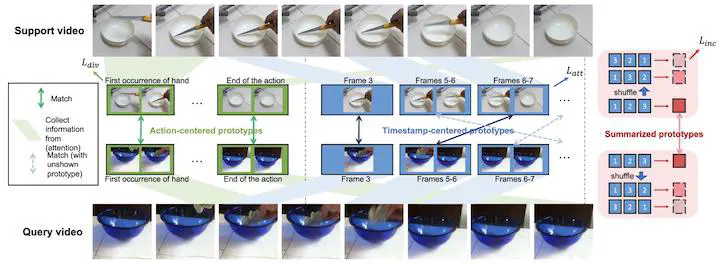
The task of few-shot action recognition aims to recognize novel action classes using only a small number of labeled training samples. How to better describe the action in each video and how to compare the similarity between videos are two of the most critical factors in this task. Directly describing the video globally or by its individual frames cannot well represent the spatiotemporal dependencies within an action. On the other hand, naively matching the global representations of two videos is also not optimal since action can happen at different locations in a video with different speeds. In this work, we propose a novel approach that describes each video using multiple types of prototypes and then computes the video similarity with a particular matching strategy for each type of prototypes. To better model the spatiotemporal dependency, we describe the video by generating prototypes that model the multi-level spatiotemporal relations via transformers. There are a total of three types of prototypes. The first type of prototypes are trained to describe specific aspects of the action in the video e.g., the start of the action, regardless of its timestamp. These prototypes are directly matched one-to-one between two videos to compare their similarity. The second type of prototypes are the timestamp-centered prototypes that are trained to focus on specific timestamps of the video. To deal with the temporal variation of actions in a video, we apply bipartite matching to allow the matching of prototypes of different timestamps. The third type of prototypes are generated from the timestamp-centered prototypes, which regularize their temporal consistency while serving as an auxiliary summarization of the whole video. Experiments demonstrate that our proposed method achieves state-of-the-art results on multiple benchmarks.