DeCo : Decomposition and Reconstruction for Compositional Temporal Grounding via Coarse-to-Fine Contrastive Ranking
概要
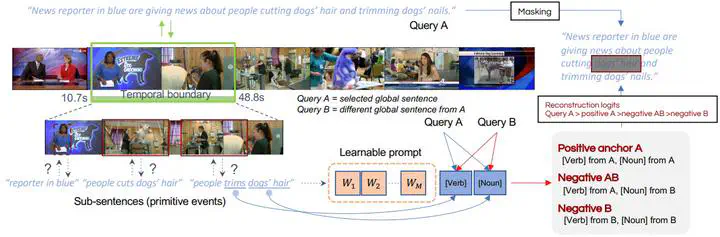
Understanding dense action in videos is a fundamental challenge towards the generalization of vision models. Several works show that compositionality is key to achieving generalization by combining known primitive elements, especially for handling novel composited structures. Compositional temporal grounding is the task of localizing dense action by using known words combined in novel ways in the form of novel query sentences for the actual grounding. In recent works, composition is assumed to be learned from pairs of whole videos and language embeddings through large scale self-supervised pre-training. Alternatively, one can process the video and language into word-level primitive elements, and then only learn fine-grained semantic correspondences. Both approaches do not consider the granularity of the compositions, where different query granularity corresponds to different video segments. Therefore, a good compositional representation should be sensitive to different video and query granularity. We propose a method to learn a coarse-to-fine compositional representation by decomposing the original query sentence into different granular levels, and then learning the correct correspondences between the video and recombined queries through a contrastive ranking constraint. Additionally, we run temporal boundary prediction in a coarse-to-fine manner for precise grounding boundary detection. Experiments are performed on two datasets Charades-CG and ActivityNet-CG showing the superior compositional generalizability of our approach.