概要
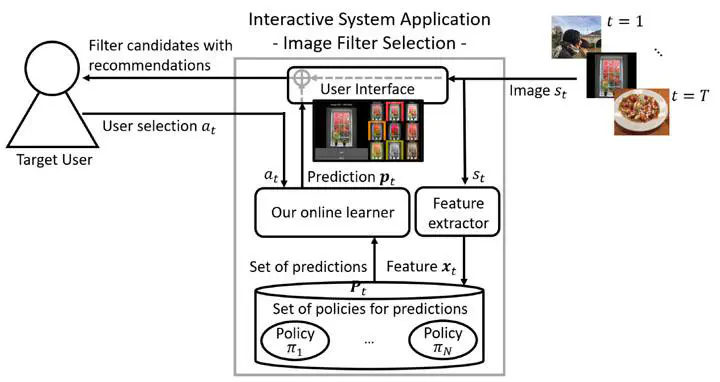
We propose two online-learning algorithms for modeling the personal preferences of users of interactive systems. The proposed algorithms leverage user feedback to estimate user behavior and provide personalized adaptive recommendation for supporting context-dependent decision-making. We formulate preference modeling as online prediction algorithms over a set of learned policies, i.e., policies generated via supervised learning with interaction and context data collected from previous users. The algorithms then adapt to a target user by learning the policy that best predicts that user’s behavior and preferences. We also generalize the proposed algorithms for a more challenging learning case in which they are restricted to a limited number of trained policies at each timestep, i.e., for mobile settings with limited resources. While the proposed algorithms are kept general for use in a variety of domains, we developed an image-filter-selection application. We used this application to demonstrate how the proposed algorithms can quickly learn to match the current user’s selections. Based on these evaluations, we show that (1) the proposed algorithms exhibit better prediction accuracy compared to traditional supervised learning and bandit algorithms, (2) our algorithms are robust under challenging limited prediction settings in which a smaller number of expert policies is assumed. Finally, we conducted a user study to demonstrate how presenting users with the prediction results of our algorithms significantly improves the efficiency of the overall interaction experience.