佐藤研究室/菅野研究室
佐藤研究室/菅野研究室
佐藤 (洋) 研究室
菅野研究室
ニュース
発表文献
連絡先
データセット
内部ページ
日本語
English
Paper-Conference
Exo2EgoDVC: Dense Video Captioning of Egocentric Procedural Activities Using Web Instructional Videos
We propose a novel benchmark for cross-view knowledge transfer of dense video captioning, adapting models from web instructional videos …
Takehiko Ohkawa
,
Takuma Yagi
,
Taichi Nishimura
,
Ryosuke Furuta
,
Atsushi Hashimoto
,
Yoshitaka Ushiku
,
Yoichi Sato
PDF
引用
ActionVOS: Action as Prompts for Video Object Segmentation
Delving into the realm of egocentric vision, the advancement of referring video object segmentation (RVOS) stands as pivotal in …
Liangyang Ouyang
,
Ruicong Liu
,
Yifei Huang
,
Ryosuke Furuta
,
Yoichi Sato
PDF
引用
ソースコード
Benchmarks and Challenges in Pose Estimation for Egocentric Hand Interactions with Objects
We interact with the world with our hands and see it through our own (egocentric) perspective. A holistic 3Dunderstanding of such …
Zicong Fan
,
Takehiko Ohkawa
,
Linlin Yang
,
Nie Lin
,
Zhishan Zhou
,
Shihao Zhou
,
Jiajun Liang
,
Zhong Gao
,
Xuanyang Zhang
,
Xue Zhang
,
Fei Li
,
Zheng Liu
,
Feng Lu
,
Karim Abou Zeid
,
Bastian Leibe
,
Jeongwan On
,
Seungryul Baek
,
Aditya Prakash
,
Saurabh Gupta
,
Kun He
,
Yoichi Sato
,
Otmar Hilliges
,
Hyung Jin Chang
,
Angela Yao
PDF
引用
Masked Video and Body-worn IMU Autoencoder for Egocentric Action Recognition
Compared with visual signals, Inertial Measurement Units (IMUs) placed on human limbs can capture accurate motion signals while being …
Mingfang Zhang
,
Yifei Huang
,
Ruicong Liu
,
Yoichi Sato
PDF
引用
WTS: A Pedestrian-Centric Traffic Video Dataset for Fine-grained Spatial-Temporal Understanding
In this paper, we address the challenge of fine-grained video event understanding in traffic scenarios, vital for autonomous driving …
Quan Kong
,
Yuki Kawana
,
Rajat Saini
,
Ashutosh Kumar
,
Jingjing Pan
,
Ta Gu
,
Yohei Ozao
,
Balazs Opra
,
David C. Anastasiu
,
Yoichi Sato
,
Norimasa Kobori
PDF
引用
Single-to-Dual-View Adaptation for Egocentric 3D Hand Pose Estimation
The pursuit of accurate 3D hand pose estimation stands as a keystone for understanding human activity in the realm of egocentric …
Ruicong Liu
,
Takehiko Ohkawa
,
Mingfang Zhang
,
Yoichi Sato
PDF
引用
ソースコード
Exo2EgoDVC: Dense Video Captioning of Egocentric Procedural Activities Using Web Instructional Videos
We propose a novel benchmark for cross-view knowledge transfer of dense video captioning, adapting models from web instructional videos …
Takehiko Ohkawa
,
Takuma Yagi
,
Taichi Nishimura
,
Ryosuke Furuta
,
Atsushi Hashimoto
,
Yoshitaka Ushiku
,
Yoichi Sato
PDF
引用
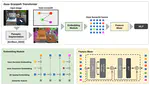
Gaze Scanpath Transformer: Predicting Visual Search Target by Spatiotemporal Semantic Modeling of Gaze Scanpath
We introduce a new method called the Gaze Scanpath Transformer for predicting a search target category during a visual search task. …
Takumi Nishiyasu
,
Yoichi Sato
PDF
引用
Ego-Exo4D: Understanding Skilled Human Activity from First- and Third-Person Perspectives
We present Ego-Exo4D, a diverse, large-scale multimodal multiview video dataset and benchmark challenge. Ego-Exo4D centers around …
Kristen Grauman
,
Andrew Westbury
,
Lorenzo Torresani
,
Kris Kitani
,
Jitendra Malik
,
Triantafyllos Afouras
,
Kumar Ashutosh
,
Vijay Baiyya
,
Siddhant Bansal
,
Bikram Boote
,
Eugene Byrne
,
Zach Chavis
,
Joya Chen
,
Feng Cheng
,
Fu-Jen Chu
,
Sean Crane
,
Avijit Dasgupta
,
Jing Dong
,
Maria Escobar
,
Cristhian Forigua
,
Abrham Gebreselasie
,
Sanjay Haresh
,
Jing Huang
,
Md Mohaiminul Islam
,
Suyog Jain
,
Rawal Khirodkar
,
Devansh Kukreja
,
Kevin J Liang
,
Jia-Wei Liu
,
Sagnik Majumder
,
Yongsen Mao
,
Miguel Martin
,
Effrosyni Mavroudi
,
Tushar Nagarajan
,
Francesco Ragusa
,
Santhosh Kumar Ramakrishnan
,
Luigi Seminara
,
Arjun Somayazulu
,
Yale Song
,
Shan Su
,
Zihui Xue
,
Edward Zhang
,
Jinxu Zhang
,
Angela Castillo
,
Changan Chen
,
Xinzhu Fu
,
Ryosuke Furuta
,
Cristina Gonzalez
,
Prince Gupta
,
Jiabo Hu
,
Yifei Huang
,
Yiming Huang
,
Weslie Khoo
,
Anush Kumar
,
Robert Kuo
,
Sach Lakhavani
,
Miao Liu
,
Mi Luo
,
Zhengyi Luo
,
Brighid Meredith
,
Austin Miller
,
Oluwatumininu Oguntola
,
Xiaqing Pan
,
Penny Peng
,
Shraman Pramanick
,
Merey Ramazanova
,
Fiona Ryan
,
Wei Shan
,
Kiran Somasundaram
,
Chenan Song
,
Audrey Southerland
,
Masatoshi Tateno
,
Huiyu Wang
,
Yuchen Wang
,
Takuma Yagi
,
Mingfei Yan
,
Xitong Yang
,
Zecheng Yu
,
Shengxin Cindy Zha
,
Chen Zhao
,
Ziwei Zhao
,
Zhifan Zhu
,
Jeff Zhuo
,
Pablo Arbelaez
,
Gedas Bertasius
,
David Crandall
,
Dima Damen
,
Jakob Engel
,
Giovanni Maria Farinella
,
Antonino Furnari
,
Bernard Ghanem
,
Judy Hoffman
,
C. v. Jawahar
,
Richard Newcombe
,
Hyun Soo Park
,
James M. Rehg
,
Yoichi Sato
,
Manolis Savva
,
Jianbo Shi
,
Mike Zheng Shou
,
Michael Wray
PDF
引用
Rotation-Constrained Cross-View Feature Fusion for Multi-View Appearance-based Gaze Estimation
Appearance-based gaze estimation has been actively studied in recent years. However, its generalization performance for unseen head …
Yoichiro Hisadome
,
Tianyi Wu
,
Jiawei Qin
,
Yusuke Sugano
PDF
引用
ソースコード
»
引用
×